Internal fault-tolerant storage
The following steps assume that an instance of MITIGATOR has already been installed. Otherwise, perform installation using one of the following methods.
Before configuring a cluster, you must configure Virtual network(VPN). It needs network connectivity between instances to work. Detailed information on setting up and the necessary access are described at the link.
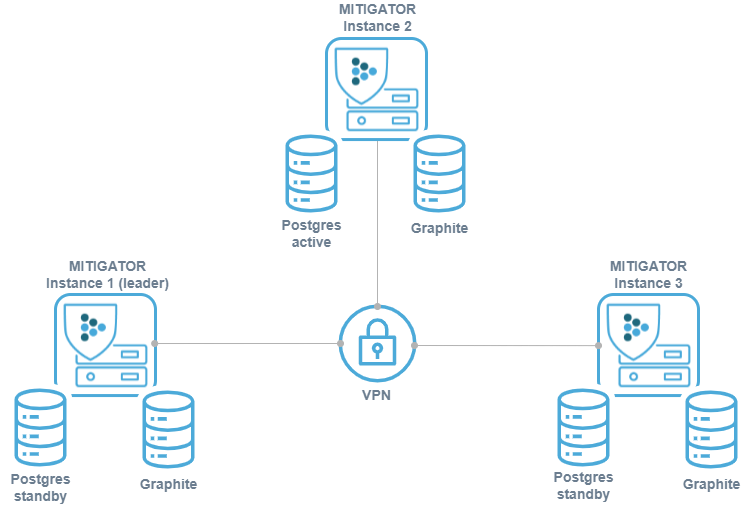
For fault tolerance, synchronized copies of the database must be physically stored on different servers (replicated). With this scheme, database replicas are stored on the same servers where MITIGATOR instances are running. This saves resources and does not require knowledge of PostgreSQL configuration.
For correct system operation all packet processors must have the same amount of system resources available.
If the cluster is assembled from MITIGATOR instances that previously worked independently, then conflicts may arise during the integration. Therefore, on all instances except the future leader, you must execute the command:
docker-compose down -v
Executing this command will delete countermeasure settings, event log, graphs, and other information stored in the databases of these instances. If the data needs to be saved, you must first perform backup.
PostgreSQL instances run in a streaming replication scheme active — hot standby. Instead of connecting directly to PostgreSQL, each MITIGATOR connects to a local running program pgfailover that redirects connections to the PostgreSQL replication leader.
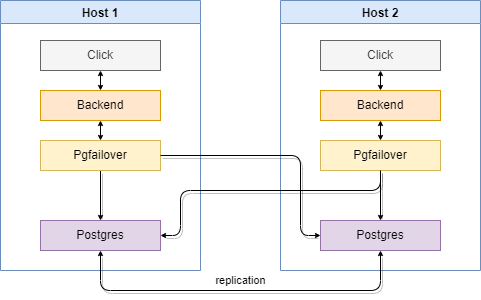
If no leader is available, pgfailover makes the leader out of one of the
slave replicas according to the given order.
The MITIGATOR cluster leader and PostgreSQL replication leader do not have to match.
It is assumed that there is reliable communication between the nodes. If a group of instances is cut off from the replication leader, a new leader (split-brain) will be selected among them. After the connection is restored, you will have to manually delete the data on the cut off part of the instances and re-enter them into the cluster (#recovery).
Metrics for graphs are written by the MITIGATOR leader for all instances for safety.
This is given by the list of servers FWSTATS_GRAPHITE_ADDRESS.
Setup
The configuration process is described for two instances and is the same on all instances,
except for the specific values of MITIGATOR_OWN_INDEX.
For more instances, you need to expand the pgfailover and pgfailover
и FWSTATS_GRAPHITE_ADDRESS.
-
Set the
MITIGATOR_HOST_ADDRESS=192.0.2.1variable in the.envfile. Where192.0.2.1is the host address for this instance. -
In the
.envfile, set the variableMITIGATOR_OWN_INDEX=0. Where0is the queue ID of this instance Must be unique and incrementing on each instance.MITIGATOR_OWN_INDEXqueue IDs do not map toown_idcluster instance IDs. -
In the
.envfile, set the variablesSERVER1=10.8.3.1andSERVER2=10.8.3.2. Where10.8.3.1and10.8.3.2are the addresses of the servers inside the VPN that are running the instances. Also, these addresses must be specified in the instance settings in the MITIGATOR web interface.If Mellanox adapters are used, the real instance addresses should be used instead of the server addresses inside the VPN.
-
Create
docker-compose.failover.ymlbased on template:wget https://docs.mitigator.ru/v22.06/dist/multi/docker-compose.failover.ymlEditing is needed if more than two instances are used. The extension is done by analogy with the two available in the template.
-
In the
.envfile, set theCOMPOSE_FILEvariable like this:COMPOSE_FILE=docker-compose.yml:docker-compose.failover.yml
Usage
-
Stand with Active base starts as usual:
docker-compose up -d -
A stand with Standby is initialized with a replica:
docker-compose run -e PGPORT=15432 postgres standbyafter which it starts as usual:
docker-compose up -d
If the connection to the leader instance (base in Active mode) is broken, the instance with databases in Standby mode takes its place and becomes the leader. The mechanism for switching the bases of the former leader to Standby mode is not provided by regular PostgreSQL replication. For a two-database scheme, this means stopping replication to the other server until the scheme is manually reconfigured.
Restoring Standby from Active
To switch the former Active and return it to the replication scheme, you must stop the PostgreSQL service and delete the local database data.
-
Stop the PostgreSQL service:
docker-compose rm -fsv postgres -
Removing local database data:
docker volume rm mitigator_postgres -
Standby initialization is similar to the first initialization:
docker-compose run -e PGPORT=15432 postgres standbythen run as usual:
docker-compose up -d
Leadership conflict
In the case of split brain, each isolated part of the cluster will have its own replication leader, that is, the cluster will split into several smaller ones (possibly from a single machine).
After pgfailover connectivity is restored, all smaller clusters will find
that there are multiple PostgreSQL servers acting as replication leaders.
n each of the clusters, an alert will be triggered about this situation,
log event «Instance leadership conflict occurred» will be generated.
In the logs of each backend-leader (docker-compose logs backend)
there will be a message like this:
time="2021-03-03T19:32:47+03:00" level=error msg=multi-conflict data="{\"primary\":0,\"rivals\":[1],\"sender\":0}" hook=on-multi-conflict
In the data field:
senderis the index of the instance that notifies on what had happened (MITIGATOR_OWN_INDEX,-indexуpgfailover).primaryis the index of the instance thatsenderreads as a valid replication leader.rivalsis a list of instance indexes on which PostgreSQL is running as a replication leader besidesprimary.
It is necessary to analyze such records in the logs of all instances, choose which one will be the leader, and make standby the rest.