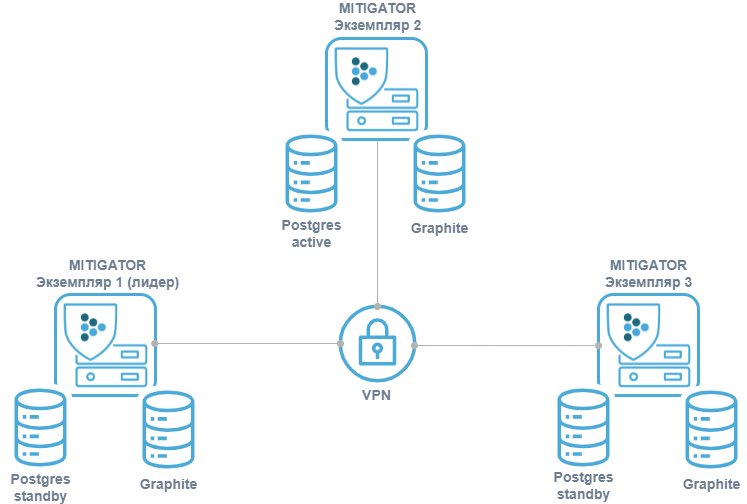
Внутреннее отказоустойчивое хранилище
Дальнейшие шаги предполагают, что экземпляр MITIGATOR уже установлен. В противном случае предварительно выполните установку одним из следующих способов.
Перед настройкой кластера необходимо настроить виртуальную сеть (VPN). Для ее работы нужна сетевая связность между экземплярами. Подробные сведения по настройке и необходимым доступам описаны по ссылке.
В целях отказоустойчивости синхронизированные копии БД должны физически храниться на разных серверах (реплицироваться). При данной схеме реплики БД хранятся на тех же серверах, где работают экземпляры MITIGATOR. Это позволяет сэкономить ресурсы и не требует знаний по настройке PostgreSQL.
Для корректной работы системы всем обработчикам пакетов должно быть доступно одинаковое количество системных ресурсов.
Если кластер собирается из экземпляров MITIGATOR, которые ранее уже работали независимо, то в ходе интеграции могут возникнуть конфликты. Поэтому на всех экземплярах кроме будущего лидера необходимо выполнить команду:
docker-compose down -vПри выполнении данной команды будут удалены настройки контрмер, журнал событий, графики и другая информация, хранимая в базах данных этих экземпляров. Если данные нужно сохранить, следует предварительно сделать резервную копию.
Экземпляры PostgreSQL работают в схеме потоковой репликации active — hot standby. Вместо подключения к PostgreSQL напрямую каждый экземпляр MITIGATOR подключается к локальной работающей программе pgfailover, которая перенаправляет подключения к текущему Primary.
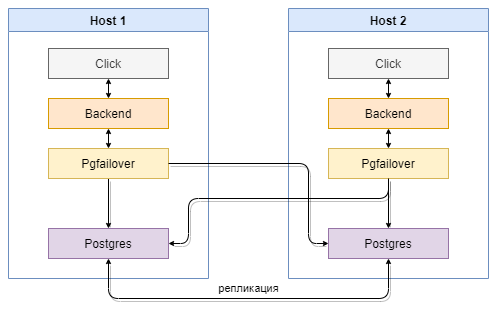
Если Primary недоступен, pgfailover повышает до Primary один из Standby
в заданной очередности.
MITIGATOR-лидер кластера и Primary могут находиться на разных экземплярах.
Предполагается, что между узлами надежная связь. Если группа экземпляров окажется отрезана от Primary, среди них будет выбран новый Primary (split-brain). После восстановления связи придется вручную удалить данные на отрезанной части экземпляров и заново ввести их в кластер.
Для отказоустойчивости в случае перехода лидерства текущий экземпляр-лидер может
записывать данные метрик на несколько серверов.
Список серверов задается переменной FWSTATS_GRAPHITE_ADDRESS сервиса fwstats.
Рекомендуется перечислить в ней адреса всех экземпляров с собственной подсистемой Graphite.
Значение по умолчанию задано в файле docker-compose.failover.yml и подразумевает
запись на два сервера.
Для улучшения отзывчивости интерфейса запросы на отрисовку графиков могут распределяться по серверам,
хранящим метрики.
Список серверов задается переменной CARBONAPI_BACKENDS сервиса carbonapi.
Рекомендуется перечислить в ней адреса всех экземпляров с собственной подсистемой Graphite.
Значение по умолчанию задано в файле docker-compose.failover.yml и подразумевает
чтение с двух доступных серверов.
Настройка
Процесс настройки описан для двух экземпляров. Для большего количества
экземпляров нужно расширить по аналогии списки серверов pgfailover,
FWSTATS_GRAPHITE_ADDRESS и CARBONAPI_BACKENDS.
pgfailover определяет локальную БД по MITIGATOR_VPN_ADDRESS экземпляра
(задаётся в настройке VPN). Это значение уникально для
каждого экземпляра, поэтому отдельной настройки не требуется. Экземпляры
без локальной БД (worker) используют docker-compose.worker.failover.yml,
в котором перевод в Primary отключён.
-
В файле
.envзадать переменнуюMITIGATOR_HOST_ADDRESS=192.0.2.1. Здесь192.0.2.1– адрес для доступа из контейнеров к хосту. Обычно это IP-адрес MGMT-интерфейса для данного экземпляра. Нежелательно использовать доменные имена: при сбоях DNS нарушится связность. -
В файле
.envзадать переменнуюMITIGATOR_PUBLIC_ADDRESS=192.0.2.1. Здесь192.0.2.1– IP-адрес или доменное имя для клиентов API и UI. Обычно совпадает по значению сMITIGATOR_HOST_ADDRESS. -
В файле
.envзадать переменныеSERVER1=10.8.3.1иSERVER2=10.8.3.2. Здесь10.8.3.1и10.8.3.2– адреса серверов внутри VPN, на которых запущены экземпляры. -
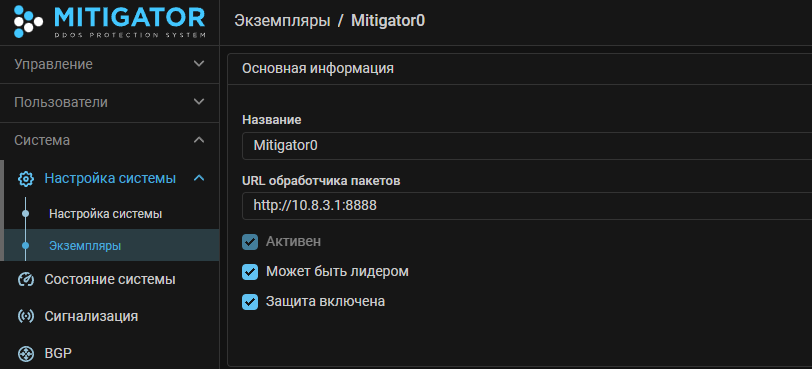
В web-интерфейсе MITIGATOR в настройках экземпляров указать реальные адреса хостов, на которых запущены обработчики пакетов.
-
Создать
docker-compose.failover.ymlна базе шаблона:wget https://docs.mitigator.ru/master/dist/multi/docker-compose.failover.ymlДля 3+ серверов или нестандартного DSN расширения вынести в
docker-compose.override.yml(переопределитьPGFAILOVER_SERVERSи, при необходимости,FWSTATS_GRAPHITE_ADDRESS,CARBONAPI_BACKENDS). -
В файле
.envзадать переменнуюCOMPOSE_FILEтак:COMPOSE_FILE=docker-compose.yml:docker-compose.failover.yml
Использование
-
Стенд с Active базой запускается как обычно:
docker-compose up -d -
Стенд с Standby инициализируется репликой:
docker-compose run --rm -e PGPORT=15432 postgres standbyпосле чего запускается как обычно:
docker-compose up -d
Если разрывается соединение с Primary, его место занимает Standby и становится новым Primary. Механизма переключения бывшего Primary в Standby не предусмотрено штатной репликацией PostgreSQL. Для схемы из двух баз данных это означает прекращение репликации на другой сервер до ручной перенастройки схемы.
Восстановление Standby из Active
Для переключения бывшего Active и возвращения его в схему репликации необходимо остановить сервис PostgreSQL, а также удалить локальные данные базы.
-
Остановка сервиса PostgreSQL с удалением анонимных томов:
docker-compose rm -fsv postgres -
Инициализация Standby аналогично первой инициализации:
docker-compose run --rm -e PGPORT=15432 postgres standbyпосле чего запускается как обычно:
docker-compose up -d
Конфликт лидерства
В случае split brain в каждой изолированной части кластера будет выбран свой Primary, то есть кластер распадется на несколько меньших (возможно, из единственной машины).
После восстановления связности pgfailover всех меньших кластеров обнаружат,
что есть несколько серверов PostgreSQL, работающих как Primary.
В каждом из кластеров сработает оповещение об этой ситуации,
будет создано событие журнала «Возник конфликт лидерства экземпляров».
В логах каждого бэкенда-лидера (docker-compose logs backend)
будет сообщение такого вида:
time="2021-03-03T19:32:47+03:00" level=error msg=multi-conflict data="{\"primary\":0,\"rivals\":[1],\"sender\":0}" hook=on-multi-conflictВ поле data:
sender— индекс экземпляра, который оповещает о произошедшем (позиция своего адреса вPGFAILOVER_SERVERS).primary— индекс того экземпляра, которыйsenderсчитает корректным Primary.rivals— список индексов экземпляров, на которых PostgreSQL работает как Primary, помимо указанного вprimary.
Необходимо проанализировать такие записи в логах всех экземпляров, выбрать, какой будет новым Primary, а остальные сделать Standby.