Работа с сервисом psg.mitigator.ru
Управление через Web-интерфейс
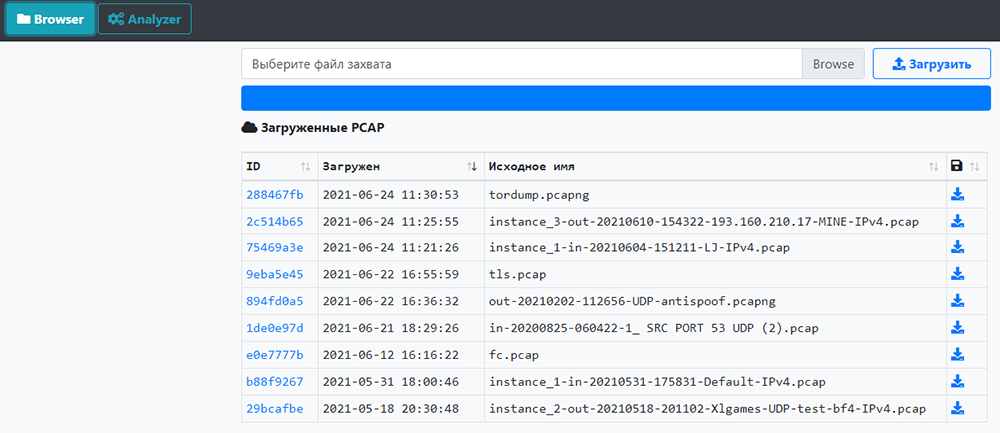
В первую очередь необходимо выбрать дамп из списка на вкладке «Browser», нажав на его ID. Дамп может быть загружен непосредственно перед выбором или выбран из ранее загруженных.
После выбора файла с дампом можно задать фильтры и выбрать способ анализа.
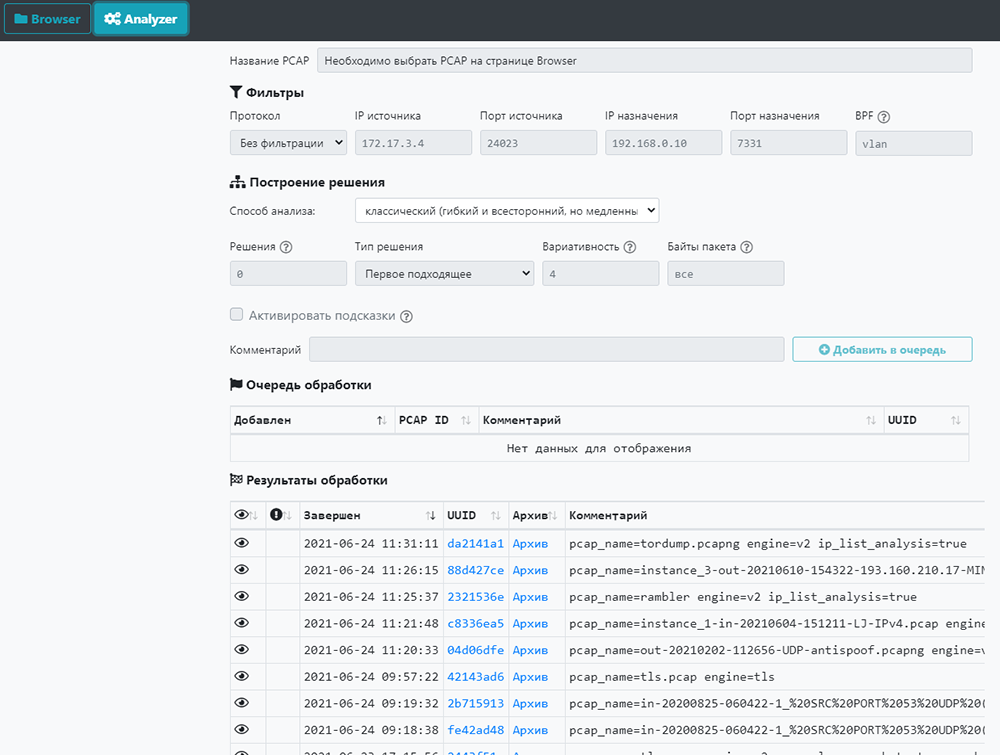
После настройки фильтров и выбора режима нужно поставить обработку дампа в очередь, нажав кнопку «Добавить в очередь». Когда анализ закончится, в таблице «Результаты обработки» появится новая строка с результатами анализа. Нажатие на «UUID» открывает подробный отчет об анализе. Нажатие на «Архив» скачивает архив с графическими данными, если они были сформированы при анализе.
Фильтры

Если заданы фильтры, то будут обрабатываться только пакеты, соответствующие фильтрам. Это нужно, если дамп «загрязнен» трафиком других приложений, или необходимо проанализировать конкретный поток.
Доступна фильтрация по:
- протоколу (tcp, udp, icmp);
- IP-адресу источника (src IP);
- порту источника (src port);
- IP-адресу назначения (dst IP);
- порту назначения (dst port);
- BPF. Произвольный фильтр, синтаксис tcpdump.
Методы анализа
Доступно три способа анализа под условными названиями:
Классический анализ
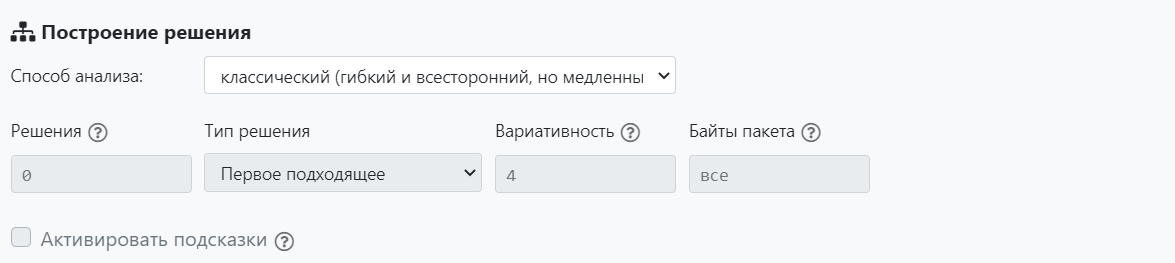
Анализирует L4 payload. Нужно указать параметры для построения дерева решений:
-
Решения — максимальная вложенность ветвления. Определяет глубину поиска в процессе построения дерева решений.
-
Тип решения — алгоритм построения дерева решений.
- Первое подходящее — поиск первого подходящего решения;
- Все возможные — поиск всех возможных решений в рамках заданной вариативности и максимального уровня вложенности;
- Решение минимальной длины — обход по веткам минимальной длины вне зависимости от полноты решения.
-
Вариативность — вариативность данных в пределах смещения для создания ветки. Максимальное число дочерних веток дерева решений.
-
Байты пакета — количество первых байт payload, которые будут анализироваться. Ограничение по количеству первых байт позволяет создать укороченные сигнатуры, например, для применения flex filter в JunOS. Уменьшает время анализа.
Отчет
Отчет состоит из секций:
-
packets stats;

- totally — всего пакетов загружено из PCAP-файла;
- filtered — количество пакетов, исключенных из обработки фильтрами;
- processed — количество обработанных пакетов.
-
protocols stats;

распределение пакетов по протоколам в процентах. -
packets payload len stats;

распределение пакетов по длине L4 payload. Абсолютное значение и процент от всех пакетов, принятых в обработку. -
[tcp, udp] [src, dst] ports stats;

Распределение пакетов по портам. Количество пакетов, процент от всех пакетов, принятых в обработку, и процент от общего числа пакетов. Выводит до 10 наиболее используемых портов среди пакетов, попавших в обработку. -
дерево решений.

описание фильтрации по L4 payload в синтаксисе контрмеры REX.
Если активировать подсказки, то в отчет будет добавлены секции:
-
values to separate into branches
Показывает смещения L4 payload c вариативностью меньше указанной и присутствующее в 100% обработанных пакетов. Если с заданной вариативностью не найдены кандидаты на ветвление, но существует во всех пакетах по какому-то смещению количество значений больше заданной вариативности, то сообщается минимальное значение для нахождения хотя бы одной ветки. -
another common values in processed payload
Показывает смещения L4 payload, которые содержат малоизменяемые значения (в более 90% пакетов, где доступно такое смещение, по нему один и тот же байт). Отображается абсолютное количество пакетов и процент от общего количества пакетов для каждого смещения. Смещения, содержащие малоизменяемые значения, но с небольшим количеством пакетов (менее 90% от общего), не отображаются. -
possible related values in processed payload
Выполняет поиск L4 payload значений, которые имеют одинаковое число повторений, скорее всего они изменяются синхронно. Отображается абсолютное количество пакетов и процент от общего количества обработанных пакетов для каждого набора связанных значений. В расчет не берутся значения, которые не меняются и встречаются очень редко (менее 5% от числа обработанных пакетов). -
possible floating values in processed payload
Выполняет поиск L4 payload значений, которые плавают в небольшом диапазоне смещений (8) и содержится во всех пакетах в рамках этого диапазона. Не учитываются значения, которые не меняются. Если найдено несколько одинаковых значений с пересекающимися диапазонами смещений, они объединяются.
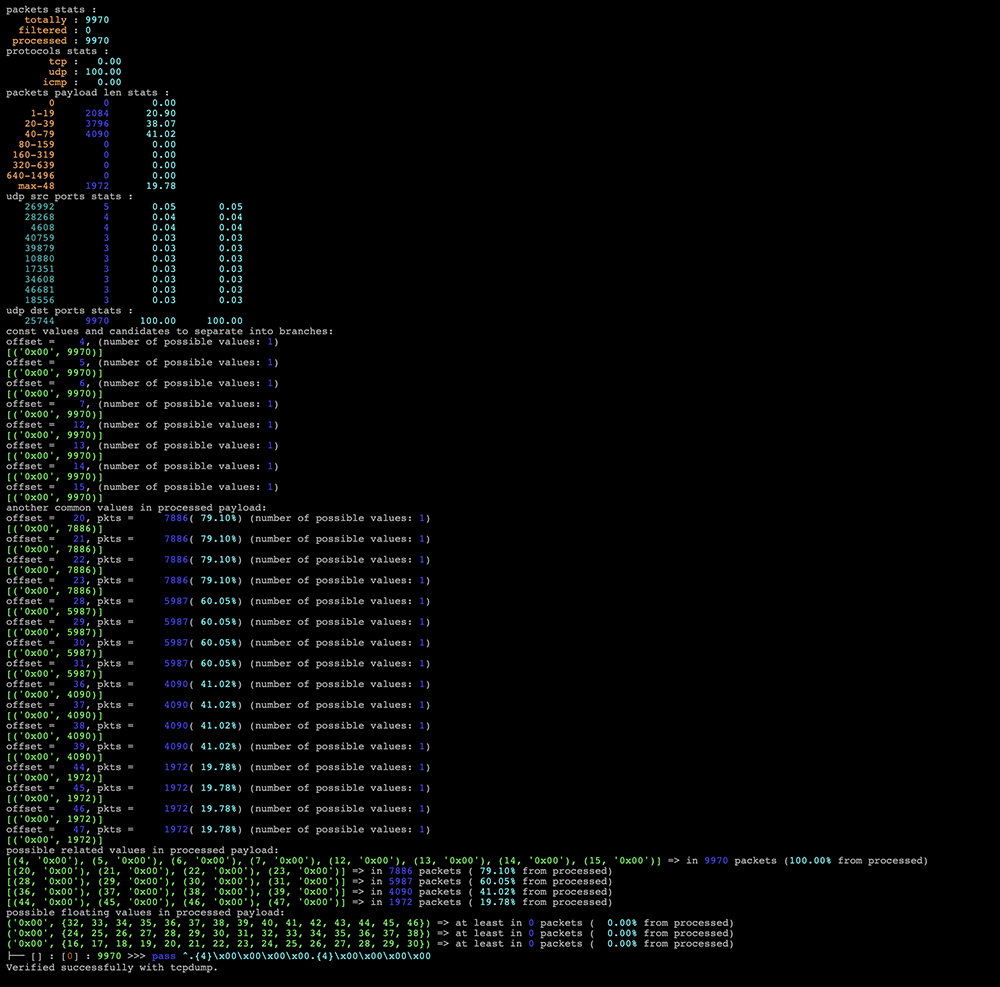
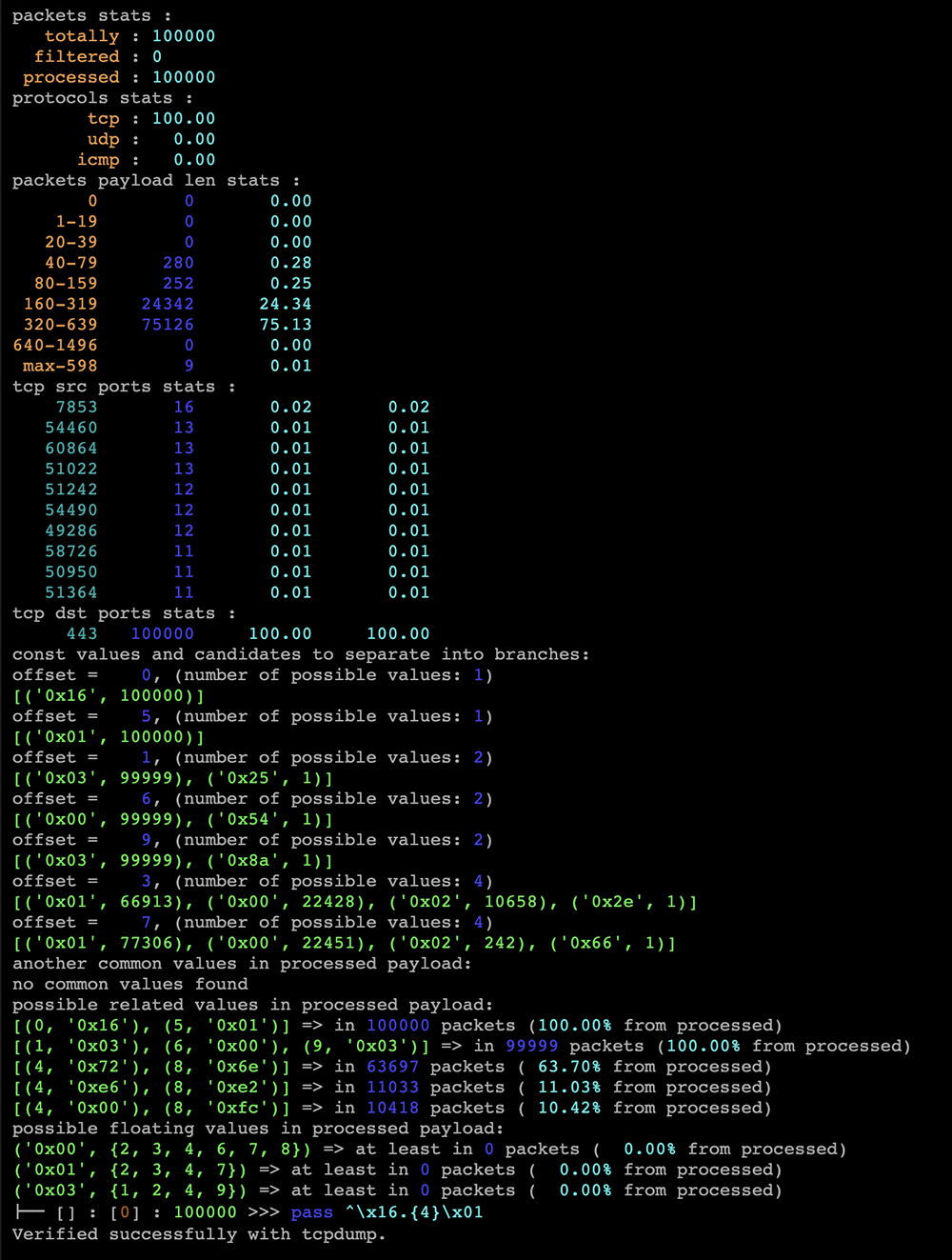
На больших файлах анализ может занимать продолжительное время. Если с параметрами по умолчанию не выделилась сигнатура, то для клиентов может быть сложно интерпретировать подсказки и корректировать параметры поиска решения. Поэтому был сделан экспериментальный метод.
Экспериментальный анализ
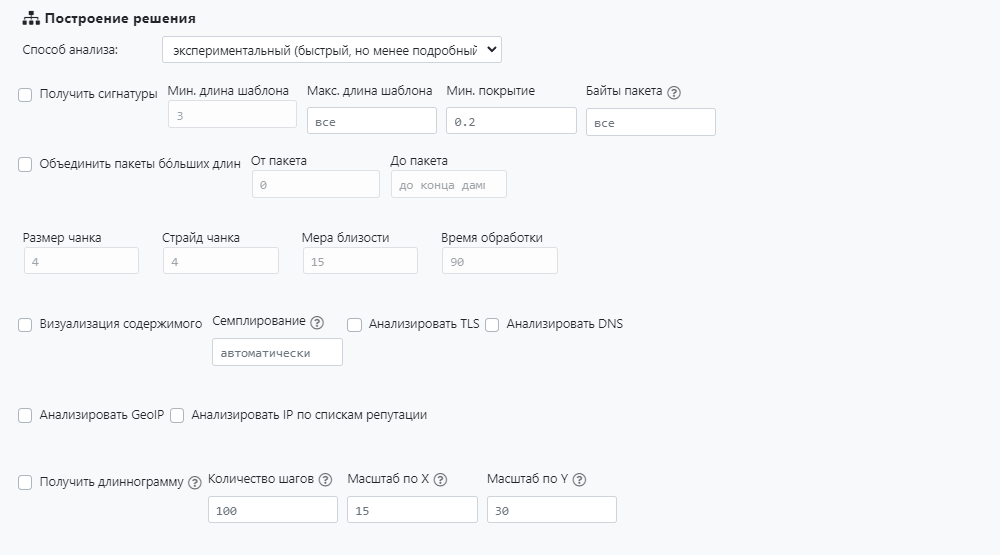
Анализирует L3/L4 заголовки и L4 payload.
Работает значительно быстрее «Классического режима», но не всегда выделяет шаблоны.
Можно задавать диапазон пакетов, которые будут подвергаться анализу, через задание значений в полях «От пакета» и «До пакета».
Для экспериментального режима можно активировать следующие чекбоксы:
- «Получить сигнатуры» — добавить в отчет шаблоны для L4 payload (см. Сигнатуры);
- «Объединить пакеты бóльших длин» — оптимизировать процесс обработки дампов;
- «Визуализация содержимого» — позволяет визуально определить закономерности в трафике (см. Визуализация содержимого);
- «Семплирование» — для построения визуализации используются только пакеты, кратные заданному значению. Например, если указано «5», то для визуалиазции будет выбран каждый пятый пакет. В режиме «автоматически» значение семплирования определяется механизмом таким образом, чтобы равномерно разместить захваченные пакеты на изображении максимальной высоты 200000 пикселей;
- «Анализировать TLS» — добавить в отчет анализ TLS сообщений;
- «Анализировать DNS» — добавить в отчет анализ DNS пакетов;
- «Анализировать GeoIP» — добавить в отчет анализ по GeoIP базам;
- «Анализировать IP по спискам репутации» — добавить в отчет анализ по репутационным спискам;
- «Получить длиннограмму» — сформировать длиннограмму (см. Длиннограмма).
Сигнатуры
Данный механизм различными способами формирует шаблоны для L4 payload.
Виды шаблонов:
- Patterns per payload lengths;
- Variable-Offset Patterns;
- Fixed Byte Mask;
- Common Submask;
- Merged Submask;
- Bloom filter signatures.
Подробное описание шаблонов см. в разделе Отчет.
Пользователем настраиваются параметры:
- «Мин. длина шаблона» — минимальное кол-во байт, которое описывает шаблон;
- «Макс. длина шаблона» — максимальное кол-во байт, которое описывает шаблон;
- «Мин. покрытие» — доля пакетов, которую должен покрывать выделенный шаблон. Например значение 0.2 означает долю в 20%. Применяется для Variable-Offset Patterns, Patterns per payload lengths;
- «Байты пакета» — длина анализируемого L4 payload от его начала;
- «Размер чанка» — размер элементарной последовательности для фильтра Блума в байтах;
- «Страйд чанка» — количество общих байтов между двумя ближайшими чанками;
- «Мера близости» — пороговое число общих единиц между двумя фильтрами Блума для определения похожести пакетов;
- «Время обработки» — максимальное время в секундах, которое система затратит на обработку фильтров Блума.
Визуализация содержимого
Визуализация содержимого может быть полезна для понимания структуры трафика, так как позволяет визуально определить закономерности в нем. Дамп представляется в виде графического изображения, в котором каждая строка — L3/L4 данные пакета. Цветом обозначены значения байтов.
При выгрузке архива пользователь получает набор файлов визуализации дампа:
- sampling#_gray256_sorted_L4.png;
- sampling#_gray256_sorted_L3_L4.png;
- sampling#_gray256_chrono_L4.png;
- sampling#_gray256_chrono_L3_L4.png;
- sampling#_color256_sorted_L4.png;
- sampling#_color256_sorted_L3_L4.png;
- sampling#_color256_chrono_L4.png;
- sampling#_color256_chrono_L3_L4.png.
Название файла говорит о методе построения визуализации:
- sampling# — показывает значение семплирования, заданное пользователем или автоматически определенное механизмом визуализации;
- sorted — пакеты выстроены по возрастанию размера payload;
- chrono — пакеты выстроены в том же порядке, в котором они захвачены в дампе (т.о. если изображение повернуть на 90 градусов против часовой стрелки, то получится классическое представление временных графиков);
- L4 — только для L4 payload;
- L3_L4 — L3 headers + L4 headers + L4 payload;
- gray — представление в оттенках серого (близкие значения байт визуально отличаются незначительно);
- color — представление в цвете (близкие значения байт хорошо визуально различимы).
Пример визуализации color256_chrono_L4:
 Пример визуализации gray256_sorted_L3_L4:
Пример визуализации gray256_sorted_L3_L4:

Длиннограмма
Механизм позволяет получить длиннограмму — изображение, показывающее распределение размера пакетов по их количеству на некотором временном интервале.
На вертикальной оси отложены временные интервалы от минимального до максимального времени захвата пакетов в микросекундах. Количество интервалов задается в поле «Количество шагов». На горизонтальной оси отмечены размеры пакетов в байтах. Цветом обозначается количество пакетов определенной длины на определенном временном интервале.
Размер точки на длиннограмме задается в пикселях через указание значений в полях «Масштаб по X» и «Масштаб по Y».
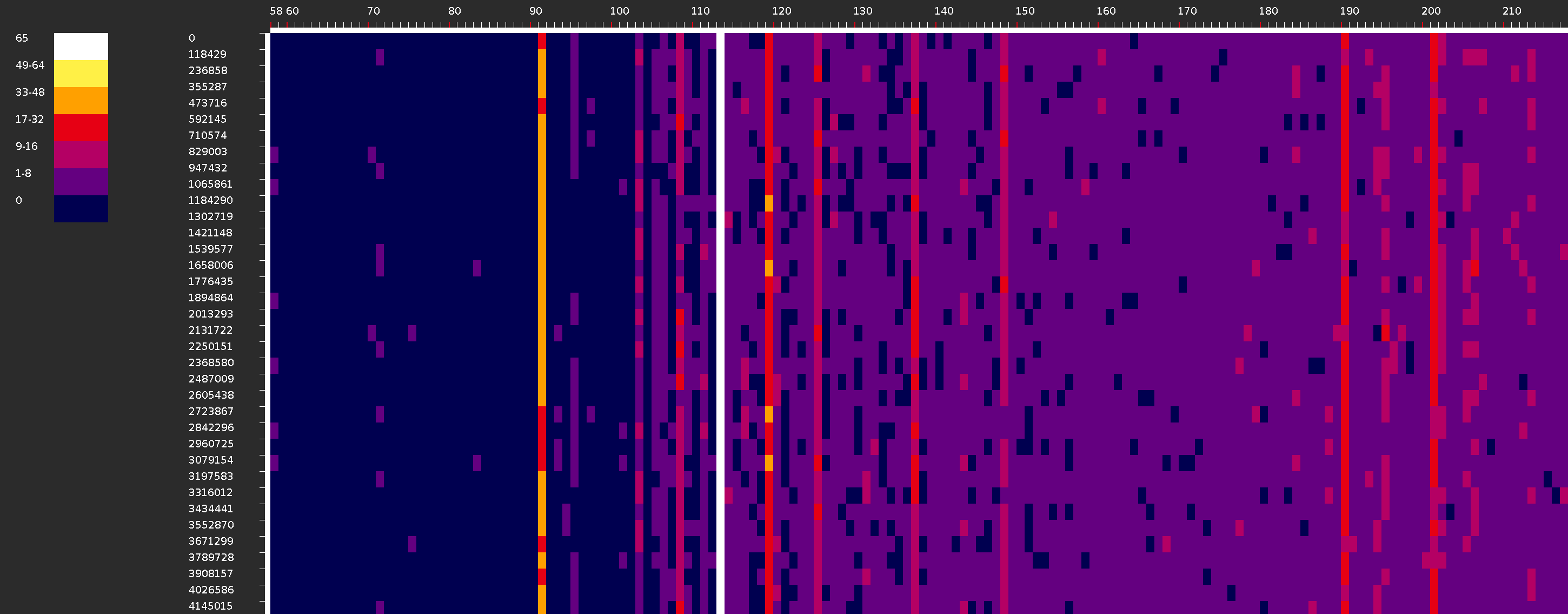
Аналогично визуализации chrono, если изображение повернуть на 90 градусов против часовой стрелки, то получится более привычное представление для спектограммы.
Отчет
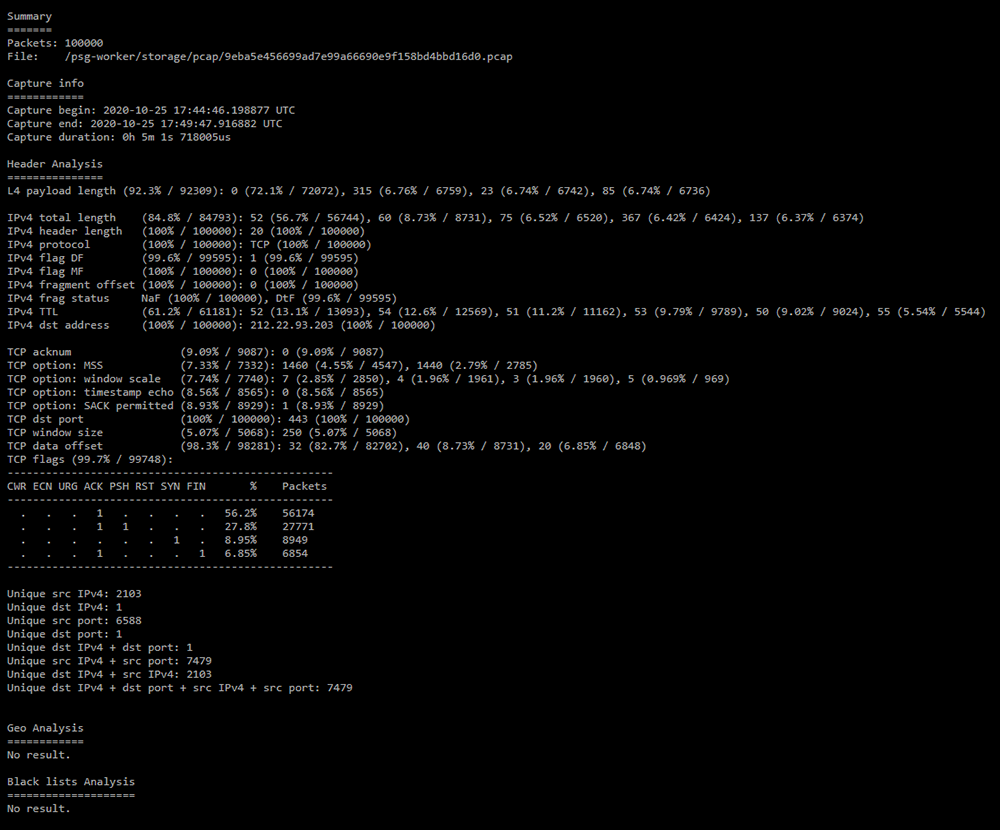
Отчет состоит из секций:
-
Summary;

- Packets — количество пакетов в дампе;
- File — путь к файлу с дампом;
- Treat large lengths as one — признак объединения пакетов наибольших длин.
-
Capture info;

- Capture begin — дата и время начала захвата;
- Capture end — дата и время окончания захвата;
- Capture duration — продолжительность захвата.
-
Header Analysis;
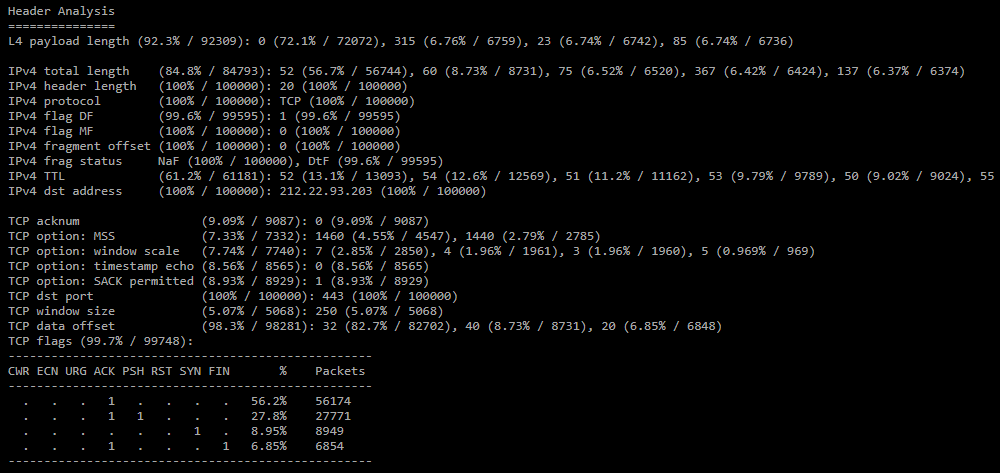
Анализ часто встречающихся значений полей в заголовках IPv4 и транспортных протоколов. Актуально, если атакующий не рандомизирует заголовки протоколов. Также формируется таблица распределения флагов по количеству пакетов. Значения показываются только если их доля в дампе 5 % и более.Формируется список уникальных сочетаний n-tupple.

-
Анализ TLS;
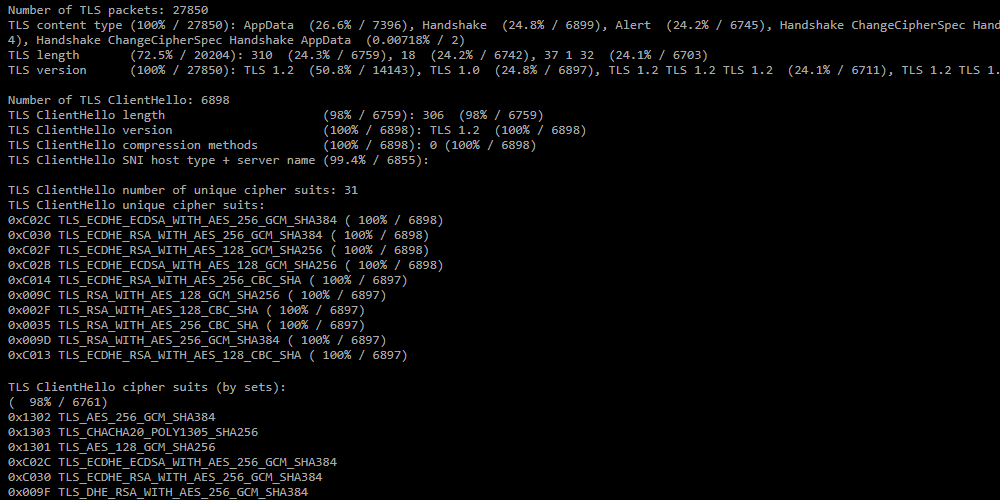 Раздел формируется в отчете, если установлен чекбокс «Анализировать TLS».
Раздел формируется в отчете, если установлен чекбокс «Анализировать TLS».- Number of TLS packets — число TLS пакетов в дампе;
- TLS content type — распределение сообщений TLS по количеству пакетов;
- TLS length — распределение по длине TLS-пакетов;
- TLS version — распределение по версии TLS;
- Number of TLS ClientHello — количество сообщений ClientHello;
- TLS ClientHello number of unique cipher suits — количество уникальных cipher suits в сообщениях ClientHello;
- TLS ClientHello unique cipher suits — перечень уникальных cipher suits;
- TLS ClientHello cipher suits (by sets) — распределение ClientHello по сочетанию наборов cipher suits;
- TLS ClientHello number of unique extensions — количество уникальных extensions;
- TLS ClientHello unique extensions — перечень уникальных extensions;
- TLS ClientHello extensions (by sets) — распределение ClientHello по сочетанию наборов extensions.
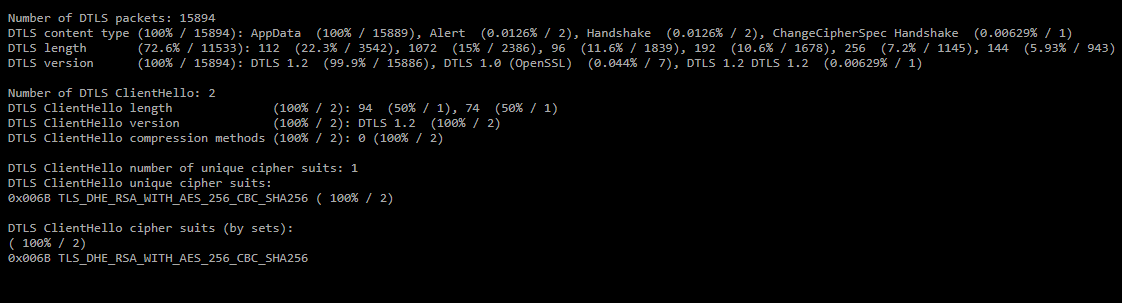 Также в отчете отображается статистика по DTLS поверх UDP.
Также в отчете отображается статистика по DTLS поверх UDP.- Number of DTLS packets — число DTLS пакетов в дампе;
- DTLS content type — распределение сообщений DTLS по количеству пакетов;
- DTLS length — распределение по длине DTLS-пакетов;
- DTLS version — распределение по версии DTLS;
- Number of DTLS ClientHello — количество сообщений ClientHello;
- DTLS ClientHello number of unique cipher suits — количество уникальных cipher suits в сообщениях ClientHello;
- DTLS ClientHello unique cipher suits — перечень уникальных cipher suits;
- DTLS ClientHello cipher suits (by sets) — распределение ClientHello по сочетанию наборов cipher suits.
- Number of TLS packets — число TLS пакетов в дампе;
-
DNS Analysis;

 Раздел формируется в отчете, если установлен чекбокс «Анализировать DNS».
Раздел формируется в отчете, если установлен чекбокс «Анализировать DNS».
Данные в отчете сгруппированы тройками, каждая из которых содержит имя домена, класс и тип query. Процент пакетов в каждой категории берется от общего числа DNS-пакетов в дампе. Для отображения тройки в отчете нужно чтобы количество DNS-пакетов одного набора превышало 5% порог от числа DNS-пакетов категории.- Number of DNS packets — количество DNS-пакетов в дампе;
- DNS UDP query — распределение DNS-пакетов c типом сообщения query, отправленных по UDP;
- DNS UDP response — распределение DNS-пакетов c типом сообщения response, отправленных по UDP и относящихся к разделу questions;
- DNS TCP query — распределение DNS-пакетов c типом сообщения query, отправленных по TCP;
- DNS TCP response — распределение DNS-пакетов c типом сообщения response, отправленных по TCP и относящихся к разделу questions.
-
Geo Analysis;
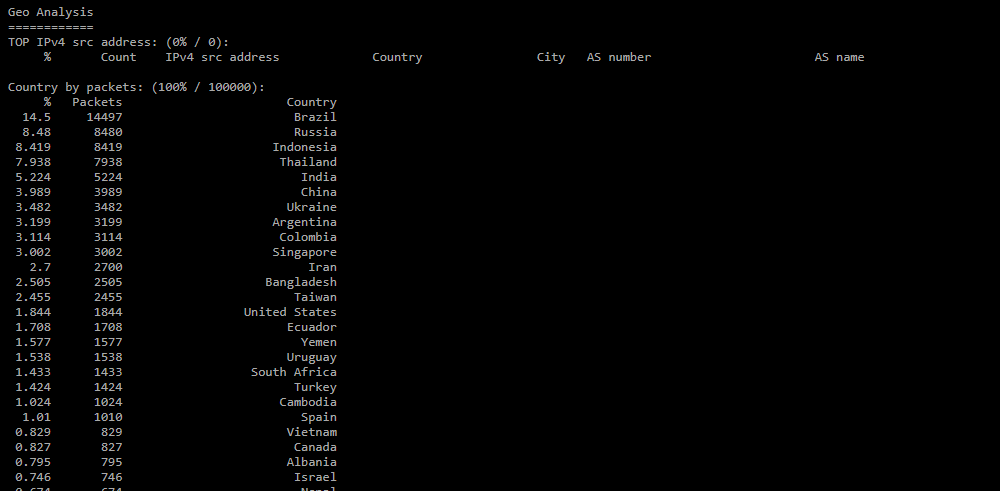
Раздел формируется в отчете, если установлен чекбокс «Анализировать GeoIP».- TOP IPv4 src address — топ IP-адресов по частоте их появления в дампе. Для каждого адреса указываются страна, город, название и номер автономной системы;
- Country by packets — распределение стран по количеству пакетов;
- Country by IPv4 count — распределение стран по количеству IP-адресов отправителей;
- AS by packets — распределение автономных систем по количеству пакетов;
- AS by IPv4 count — распределение автономных систем по количеству IP-адресов отправителей.
-
IP lists Analysis;
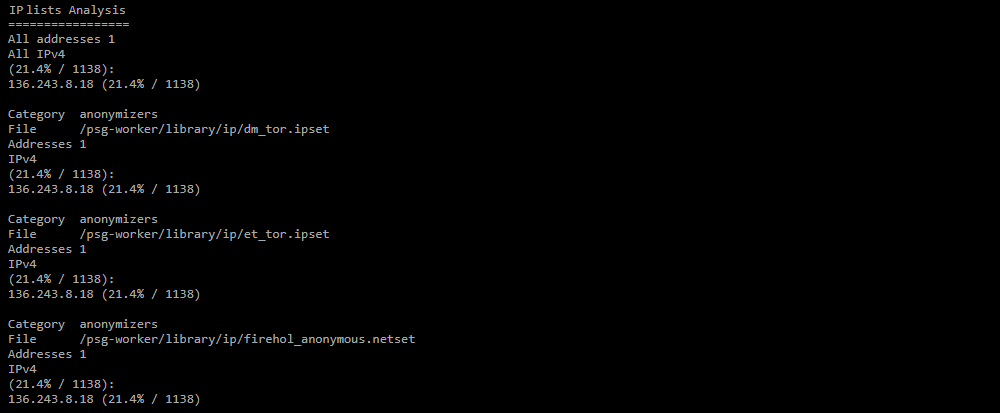
Анализ IP-адресов дампа по различным репутационным спискам. Раздел формируется в отчете, если установлен чекбокс «Анализировать IP по спискам репутации».- All addresses — количество IP-адресов, по которым обнаружено вхождение в репутационные списки;
- Category — тип списка, в котором обнаружено вхождение.
-
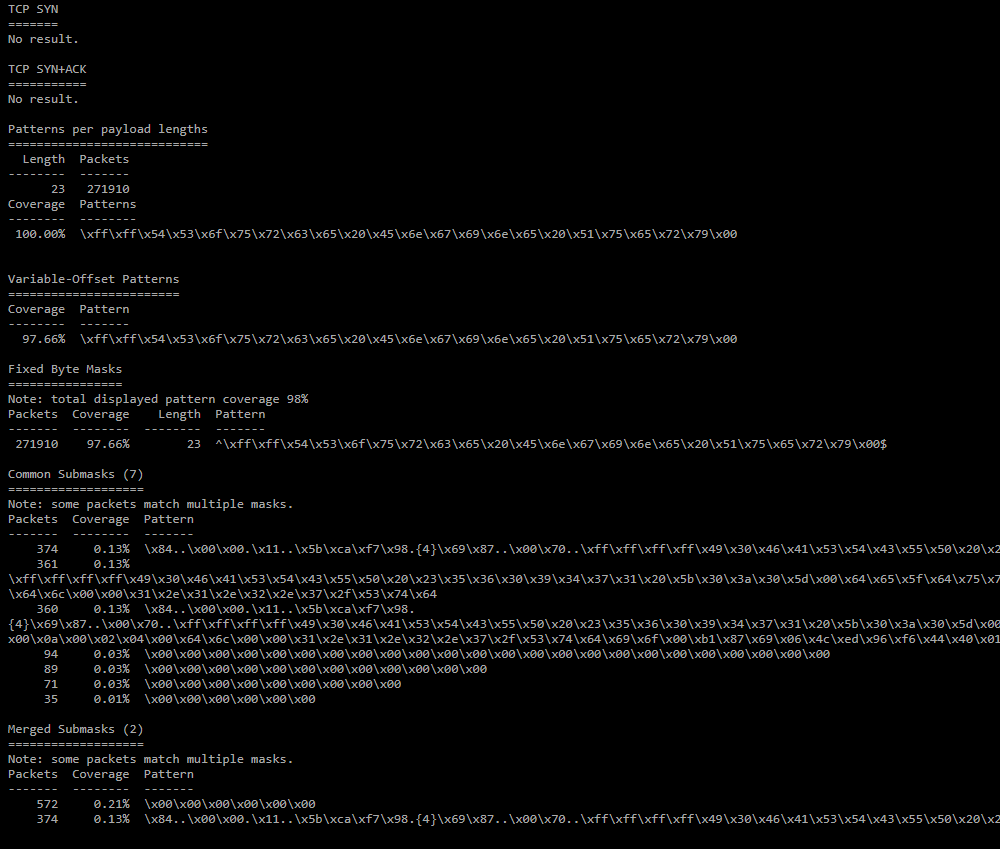
TCP SYN;
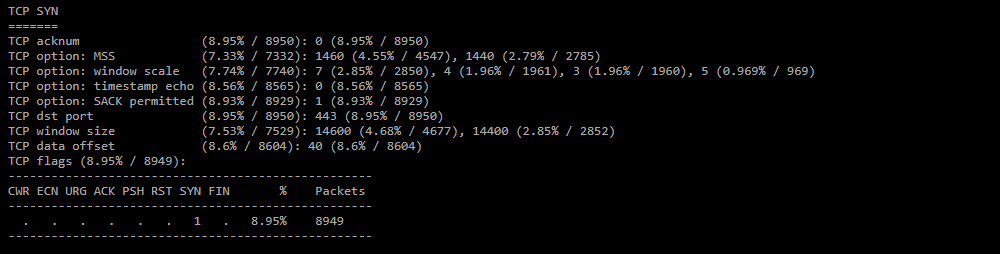
Статистика по TCP заголовкам для SYN пакетов. -
TCP SYN+ACK;
Статистика по TCP заголовкам для SYN+ACK пакетов аналогична статистике для SYN пакетов. -
Patterns per payload lengths;

Часто наблюдаемые шаблоны для пакетов с наиболее часто встречающейся длиной. -
Variable-Offset Patterns;

Часто наблюдаемые шаблоны в payload с переменным смещением. -
Fixed Byte Mask;

Смещения, по которым значение байта фиксировано, набор таких смещений и значений по ним образуем маску. -
Common Submask;
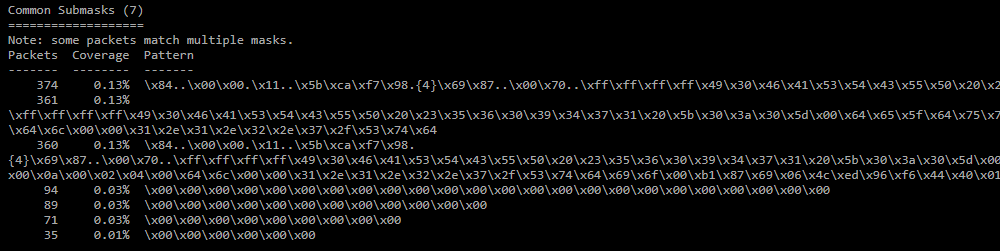
Среди масок ищутся похожие (50% совпадения регулярных выражений), и из них выделяется общая часть. -
Merged Submask;

Из common submasks удаляются избыточные маски, например, aabb покрывается aab и остается только aab.
-
Bloom filter signatures;
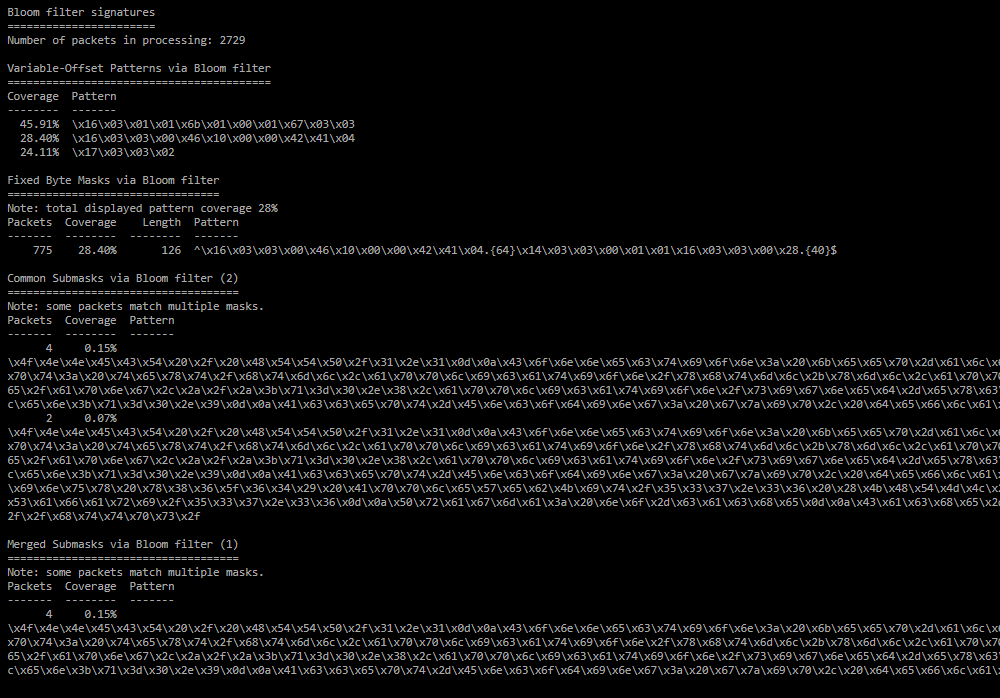
Список сигнатур для похожих пакетов, которые обнаружены при помощи фильтров Блума.- Number of packets in processing — количество пакетов, среди которых выбирались похожие;
- Variable-Offset Patterns via Bloom filter — Variable-Offset Patterns для похожих пакетов;
- Fixed Byte Masks via Bloom filter — Fixed Byte Mask для похожих пакетов;
- Common Submasks via Bloom filter — Common Submask для похожих пакетов;
- Merged Submasks via Bloom filter — Merged Submask для похожих пакетов.
Анализ TLS

Данный метод выделяет из PCAP для TLS трафика JA3-отпечатки. Результаты выдаются в CSV, чтобы их было удобно анализировать в других средствах, от Excel до Jupyter.
Отчет
Отчет состоит из трех секций:
-
Summary;

- Packets total — количество пакетов в дампе;
- Packets filtered — количество проанализированных пакетов;
- ClientHello — количество найденных ClientHello;
- Fingerprints — количество уникальных отпечатков.
-
Fingerprints;
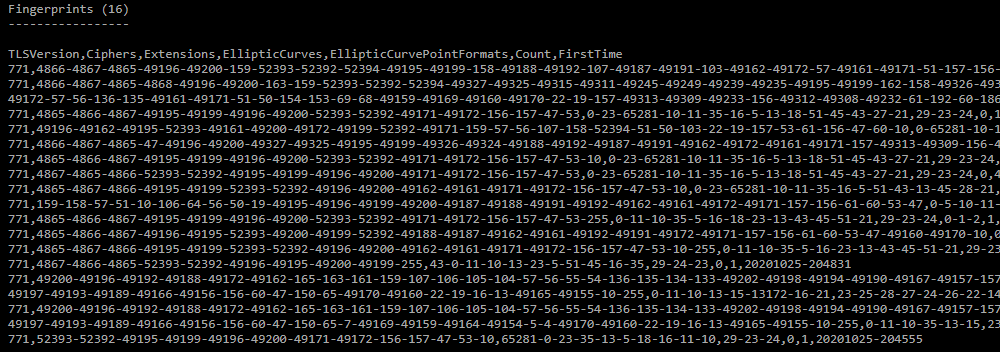
Список уникальных отпечатков в формате загрузки в контрмеру ATLS. Список отсортирован в порядке убывания количества отпечатков в дампе. -
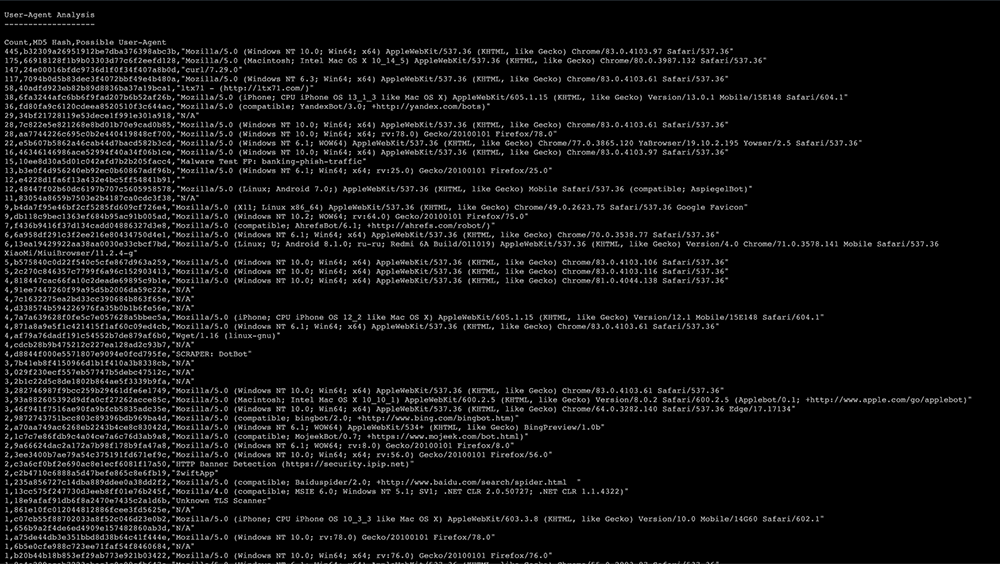
User-Agent Analysis;
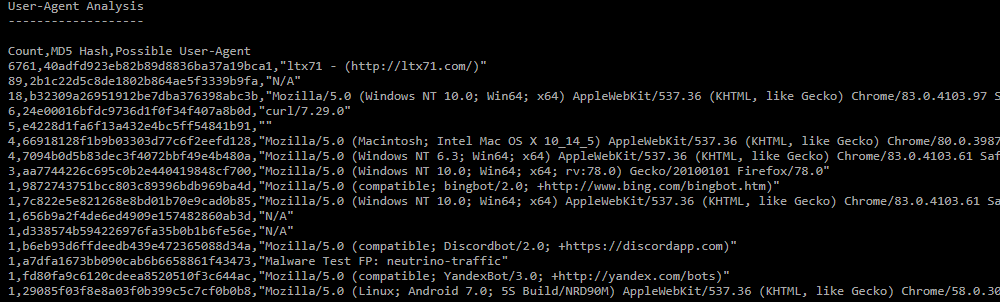
Дополнительная секция, предназначенная для пользователя. Для каждого уникального отпечатка:- Count, сколько раз найден отпечаток в дампе;
- MD5 Hash, для поиска информации во внешних источниках;
- Possible User-Agent, подсказка по User-Agent.