Экспериментальный способ анализа
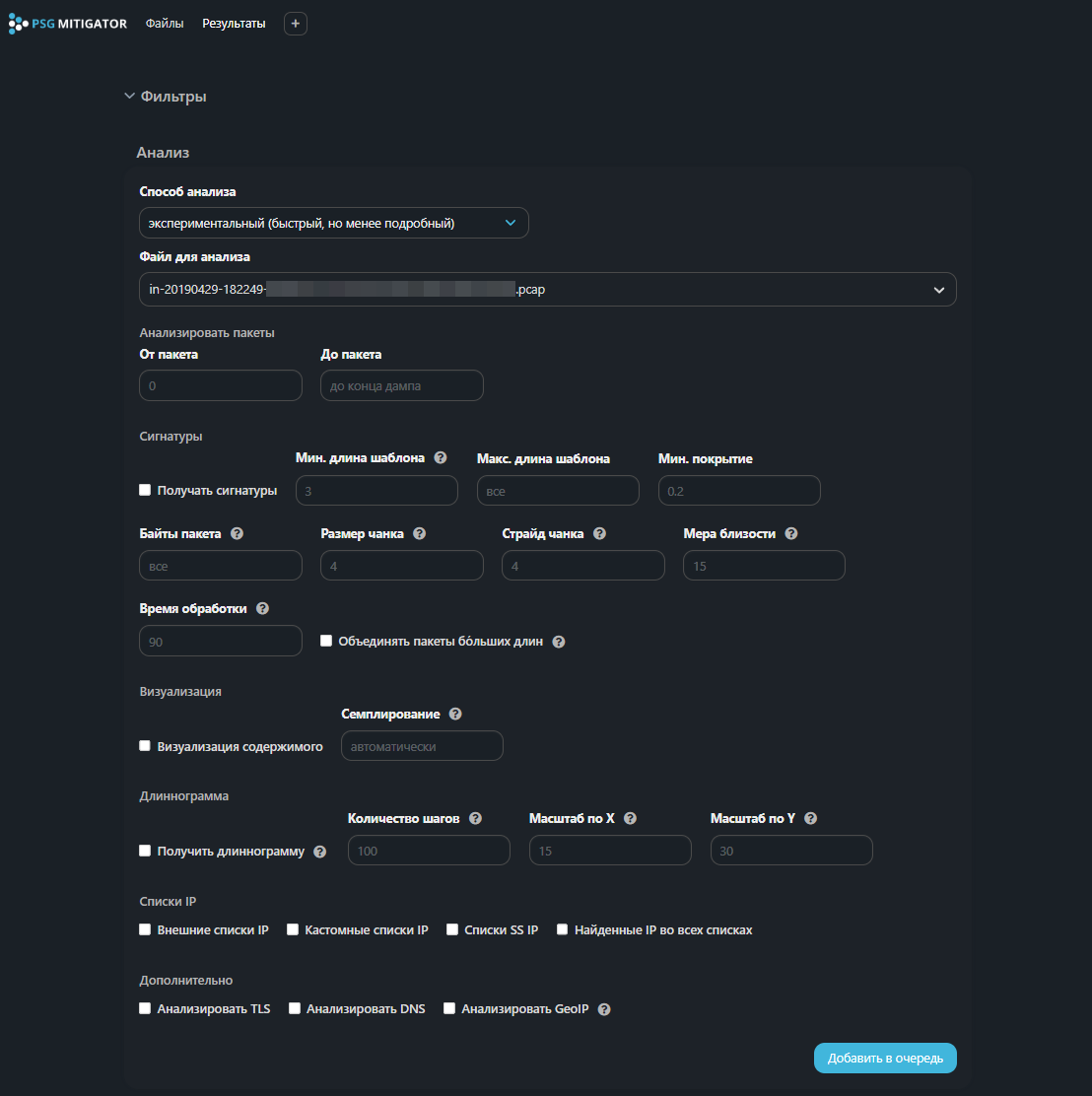
Анализирует L3/L4 заголовки и L4 payload.
Можно задавать диапазон пакетов, которые будут подвергаться анализу, через задание значений в полях “От пакета” и “До пакета”.
Для экспериментального режима можно активировать следующие чекбоксы:
- “Получить сигнатуры” — добавить в отчет шаблоны для L4 payload (см. Сигнатуры);
- “Объединить пакеты бóльших длин” — оптимизировать процесс обработки дампов;
- “Визуализация содержимого” — позволяет визуально определить закономерности в трафике (см. Визуализация содержимого);
- “Семплирование” — для построения визуализации используются только пакеты, кратные заданному значению. Например, если указано “5”, то для визуалиазции будет выбран каждый пятый пакет. В режиме “автоматически” значение семплирования определяется механизмом таким образом, чтобы равномерно разместить захваченные пакеты на изображении максимальной высоты 200000 пикселей;
- “Получить длиннограмму” — сформировать длиннограмму (см. Длиннограмма);
- “Внешние списки IP” — добавить в отчет анализ по внешним репутационным спискам;
- “Кастомные списки IP” — добавить в отчет анализ по дополнительным репутационным спискам;
- “Списки SS IP” — добавить в отчет анализ по репутационным спискам с сервера статистики;
- “Найденные IP во всех списках” — добавить в отчет IP-адреса, по которым обнаружено вхождение хотя бы в один из выбранных репутационных списков;
- “Анализировать TLS” — добавить в отчет анализ TLS сообщений;
- “Анализировать DNS” — добавить в отчет анализ DNS пакетов;
- “Анализировать GeoIP” — добавить в отчет анализ по GeoIP базам.
Сигнатуры
Данный механизм различными способами формирует шаблоны для L4 payload.
Виды шаблонов:
- Patterns per payload lengths;
- Variable-Offset Patterns;
- Fixed Byte Mask;
- Common Submask;
- Merged Submask;
- Bloom filter signatures.
Подробное описание шаблонов см. в разделе Отчет.
Пользователем настраиваются параметры:
- “Мин. длина шаблона” — минимальное кол-во байт, которое описывает шаблон;
- “Макс. длина шаблона” — максимальное кол-во байт, которое описывает шаблон;
- “Мин. покрытие” — доля пакетов, которую должен покрывать выделенный шаблон. Например значение 0.2 означает долю в 20%. Применяется для Variable-Offset Patterns, Patterns per payload lengths;
- “Байты пакета” — длина анализируемого L4 payload от его начала;
- “Размер чанка” — размер элементарной последовательности для фильтра Блума в байтах;
- “Страйд чанка” — количество общих байтов между двумя ближайшими чанками;
- “Мера близости” — пороговое число общих единиц между двумя фильтрами Блума для определения похожести пакетов;
- “Время обработки” — максимальное время в секундах, которое система затратит на обработку фильтров Блума.
Визуализация содержимого
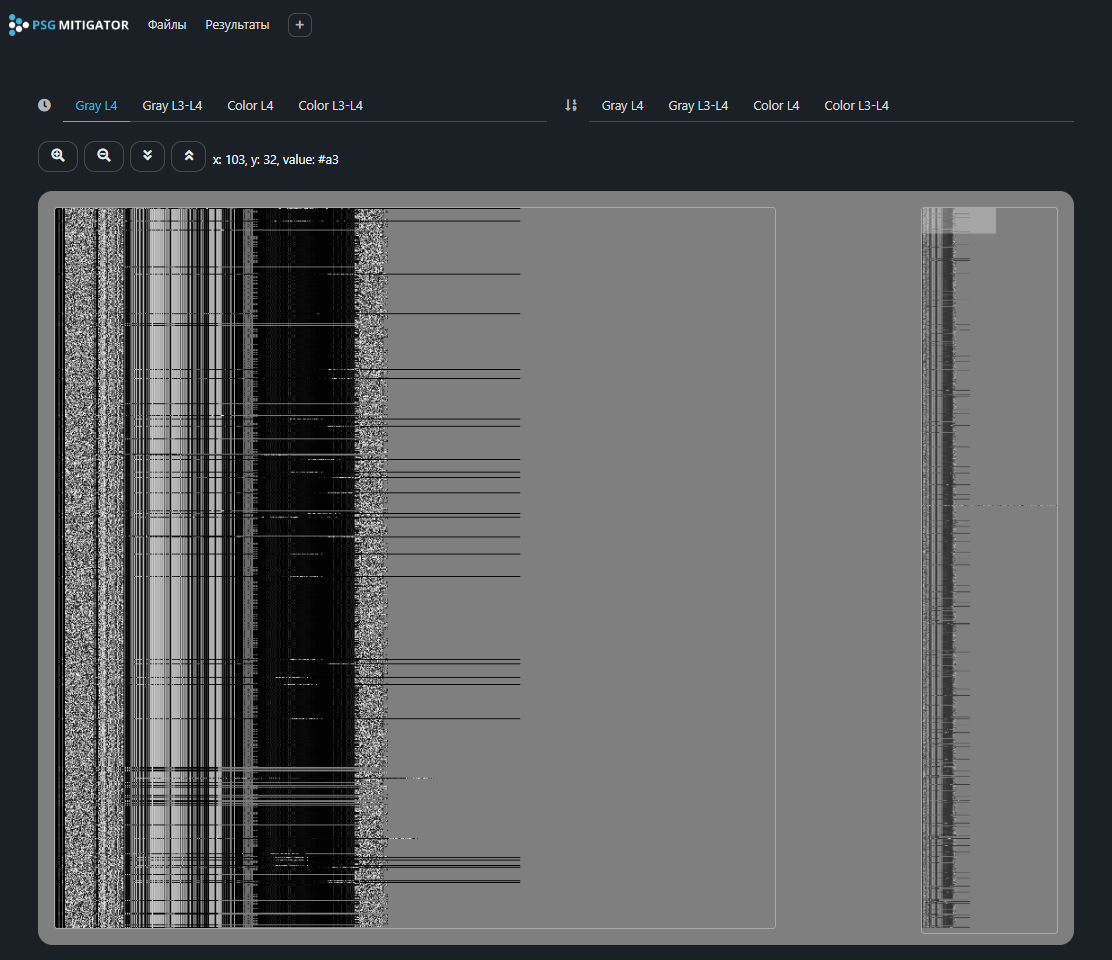
Визуализация содержимого может быть полезна для понимания структуры трафика, так как позволяет визуально определить закономерности в нем. Дамп представляется в виде графического изображения, в котором каждая строка — L3/L4 данные пакета. Цветом обозначены значения байтов. Построенная в ходе анализа визуализация может быть скачана в виде архива при нажатии на иконку с файлом или просмотрена в браузере при нажатии на иконку с гистограммой.
При выгрузке архива пользователь получает набор файлов визуализации дампа:
- sampling#_gray256_sorted_L4.png;
- sampling#_gray256_sorted_L3_L4.png;
- sampling#_gray256_chrono_L4.png;
- sampling#_gray256_chrono_L3_L4.png;
- sampling#_color256_sorted_L4.png;
- sampling#_color256_sorted_L3_L4.png;
- sampling#_color256_chrono_L4.png;
- sampling#_color256_chrono_L3_L4.png.
Название файла говорит о методе построения визуализации:
- sampling# — показывает значение семплирования, заданное пользователем или автоматически определенное механизмом визуализации;
- sorted — пакеты выстроены по возрастанию размера payload;
- chrono — пакеты выстроены в том же порядке, в котором они захвачены в дампе (т.о. если изображение повернуть на 90 градусов против часовой стрелки, то получится классическое представление временных графиков);
- L4 — только для L4 payload;
- L3_L4 — L3 headers + L4 headers + L4 payload;
- gray — представление в оттенках серого (близкие значения байт визуально отличаются незначительно);
- color — представление в цвете (близкие значения байт хорошо визуально различимы).
Пример визуализации color256_chrono_L4:
 Пример визуализации gray256_sorted_L3_L4:
Пример визуализации gray256_sorted_L3_L4:

При просмотре в браузере удобно переключаться между различными методами построения визуализации. Слева отображаются четыре варианта изображений с сортировкой по времени захвата, справа — четыре варианта с сортировкой по возрастанию размера payload. Область представления разделена на две части, в левой находится экран визуализации, в правой — карта визуализации. Кнопками управления можно изменять масштаб отображения и скорость прокрутки. Рядом с кнопками управления отображаются координаты курсора и значение на изображении в указанной точке.
Длиннограмма
Механизм позволяет получить длиннограмму — изображение, показывающее распределение размера пакетов по их количеству на некотором временном интервале.
На вертикальной оси отложены временные интервалы от минимального до максимального времени захвата пакетов в микросекундах. Количество интервалов задается в поле “Количество шагов”. На горизонтальной оси отмечены размеры пакетов в байтах. Цветом обозначается количество пакетов определенной длины на определенном временном интервале.
Размер точки на длиннограмме задается в пикселях через указание значений в полях “Масштаб по X” и “Масштаб по Y”.
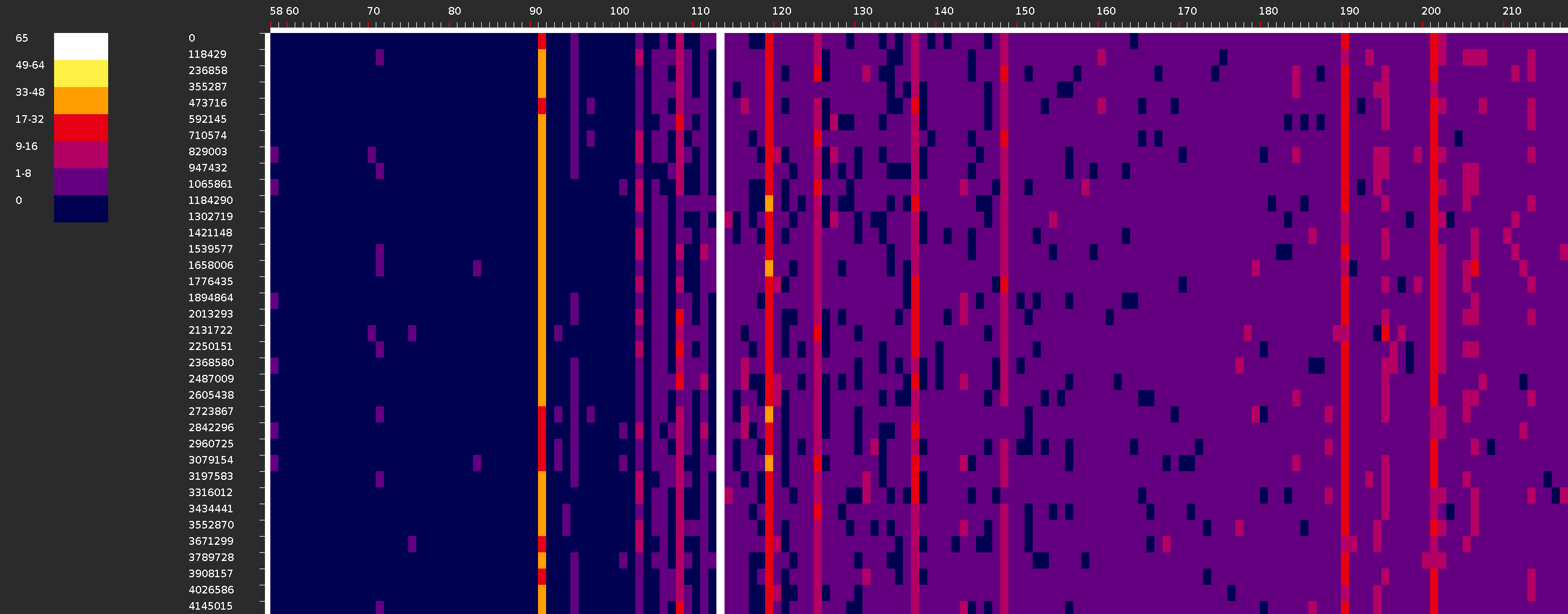
Аналогично визуализации chrono, если изображение повернуть на 90 градусов против часовой стрелки, то получится более привычное представление для спектограммы.
Отчет
В шапке отчета отображаются баннер с названием сервиса, название способа анализа, время его начала и параметры, а также название файла с дампом.
Отчет состоит из секций:
-
Summary;

- Packets — количество пакетов в дампе;
- File — путь к файлу с дампом;
- Treat large lengths as one — признак объединения пакетов наибольших длин.
-
Capture info;

- Capture begin — дата и время начала захвата;
- Capture end — дата и время окончания захвата;
- Capture duration — продолжительность захвата.
-
Header Analysis;
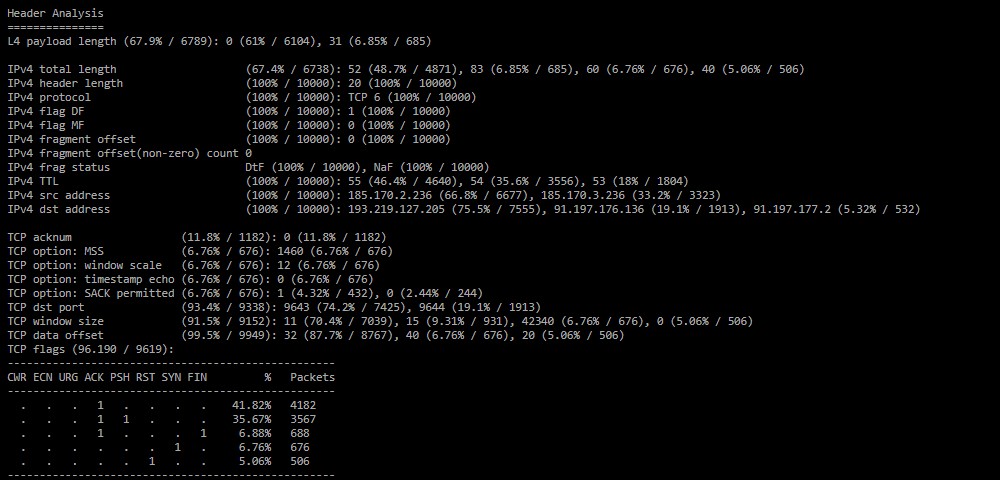
Анализ часто встречающихся значений полей в заголовках IPv4 и транспортных протоколов. Актуально, если атакующий не рандомизирует заголовки протоколов. Значения показываются только если доля пакетов определенного протокола в дампе 5 % и более. Показывается распределение фрагментированных пакетов с ненулевым значением смещения в IP заголовке и количество уникальных ненулевых смещений. Также формируется таблица распределения TCP-флагов по количеству пакетов.В поле IPv4 frag status формируется распределение по флагам фрагментации в синтаксисе ACL.
NaF – (Not a fragment) пакет не является фрагментом; Dtf – (Don't fragment) запрет фрагментации; IsF – (Is a fragment) пакет является фрагментом; FF – (First fragment) признак первого фрагмента; LF – (Last fragment) признак последнего фрагмента.Формируется список уникальных сочетаний n-tupple.

-
TLS Analysis;
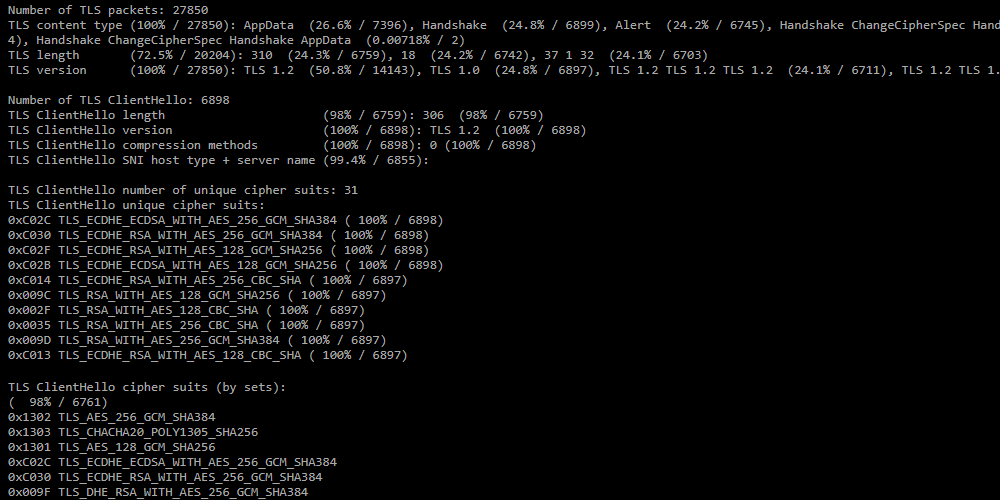 Раздел формируется в отчете, если установлен чекбокс “Анализировать TLS”.
Раздел формируется в отчете, если установлен чекбокс “Анализировать TLS”.- Number of TLS packets — число TLS пакетов в дампе;
- TLS content type — распределение сообщений TLS по количеству пакетов;
- TLS length — распределение по длине TLS-пакетов;
- TLS version — распределение по версии TLS;
- Number of TLS ClientHello — количество сообщений ClientHello;
- TLS ClientHello number of unique cipher suits — количество уникальных cipher suits в сообщениях ClientHello;
- TLS ClientHello unique cipher suits — перечень уникальных cipher suits;
- TLS ClientHello cipher suits (by sets) — распределение ClientHello по сочетанию наборов cipher suits;
- TLS ClientHello number of unique extensions — количество уникальных extensions;
- TLS ClientHello unique extensions — перечень уникальных extensions;
- TLS ClientHello extensions (by sets) — распределение ClientHello по сочетанию наборов extensions.
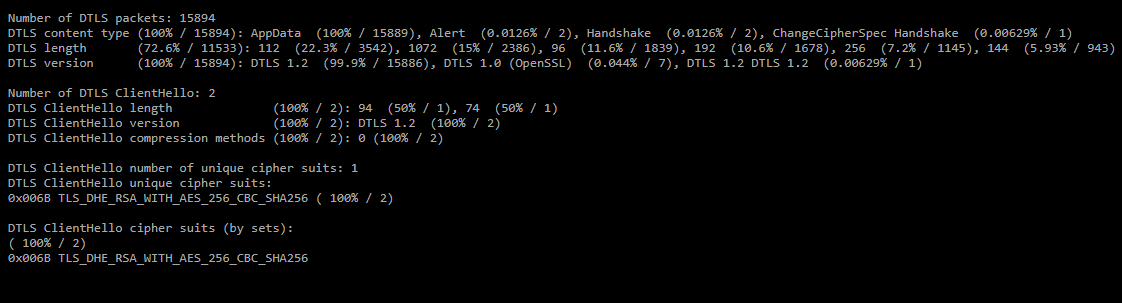 Также в отчете отображается статистика по DTLS поверх UDP.
Также в отчете отображается статистика по DTLS поверх UDP.- Number of DTLS packets — число DTLS пакетов в дампе;
- DTLS content type — распределение сообщений DTLS по количеству пакетов;
- DTLS length — распределение по длине DTLS-пакетов;
- DTLS version — распределение по версии DTLS;
- Number of DTLS ClientHello — количество сообщений ClientHello;
- DTLS ClientHello number of unique cipher suits — количество уникальных cipher suits в сообщениях ClientHello;
- DTLS ClientHello unique cipher suits — перечень уникальных cipher suits;
- DTLS ClientHello cipher suits (by sets) — распределение ClientHello по сочетанию наборов cipher suits.
- Number of TLS packets — число TLS пакетов в дампе;
-
DNS Analysis;

 Раздел формируется в отчете, если установлен чекбокс “Анализировать DNS”.
Раздел формируется в отчете, если установлен чекбокс “Анализировать DNS”.
Данные в отчете сгруппированы тройками, каждая из которых содержит имя домена, класс и тип query. Процент пакетов в каждой категории берется от общего числа DNS-пакетов в дампе. Для отображения тройки в отчете нужно чтобы количество DNS-пакетов одного набора превышало 5% порог от числа DNS-пакетов категории.- Number of DNS packets — количество DNS-пакетов в дампе;
- DNS UDP query — распределение DNS-пакетов c типом сообщения query, отправленных по UDP;
- DNS UDP response — распределение DNS-пакетов c типом сообщения response, отправленных по UDP и относящихся к разделу questions;
- DNS TCP query — распределение DNS-пакетов c типом сообщения query, отправленных по TCP;
- DNS TCP response — распределение DNS-пакетов c типом сообщения response, отправленных по TCP и относящихся к разделу questions.
-
Geo Analysis;
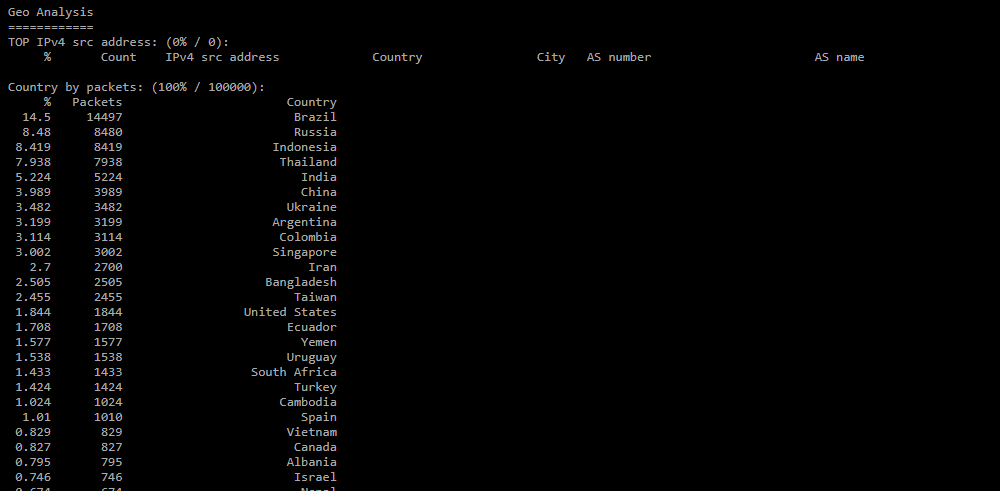
Раздел формируется в отчете, если установлен чекбокс “Анализировать GeoIP”.- TOP IPv4 src address — топ IP-адресов по частоте их появления в дампе. Для каждого адреса указываются страна, город, название и номер автономной системы;
- Country by packets — распределение стран по количеству пакетов;
- Country by IPv4 count — распределение стран по количеству IP-адресов отправителей;
- AS by packets — распределение автономных систем по количеству пакетов;
- AS by IPv4 count — распределение автономных систем по количеству IP-адресов отправителей.
-
IP lists Analysis;

Анализ IP-адресов дампа по репутационным спискам. Раздел формируется в отчете, если установлен чекбокс “Анализировать IP по спискам репутации”.В секции приводятся список всех IP-адресов, по которым обнаружено вхождение в репутационные списки этой категории, затем вхождение по каждому списку c указанием названия списка и количества вхождений;

-
Custom IP lists Analysis;
 Анализ IP-адресов дампа по дополнительным репутационным спискам. Раздел формируется в отчете,
если установлен чекбокс “Анализировать IP по спискам репутации”.
Анализ IP-адресов дампа по дополнительным репутационным спискам. Раздел формируется в отчете,
если установлен чекбокс “Анализировать IP по спискам репутации”.В секции приводятся список всех IP-адресов, по которым обнаружено вхождение дополнительные репутационные списки, затем вхождение по каждому списку, затем вхождение по каждому списку c указанием названия списка и количества вхождений;
-
SS feed IP lists Analysis;
 Анализ IP-адресов дампа по репутационным спискам с сервера статистики. Раздел формируется
в отчете, если установлен чекбокс “Анализировать IP по спискам репутации”.
Анализ IP-адресов дампа по репутационным спискам с сервера статистики. Раздел формируется
в отчете, если установлен чекбокс “Анализировать IP по спискам репутации”.В секции приводятся список IP-адресов, по которым обнаружено вхождение в репутационные списки, сформированные на сервере статистики за различные временные интервалы, затем вхождение по каждому списку;
-
Matched IPs in all IP lists;

В секции приводятся списки IP-адресов, по которым обнаружено вхождение хотя бы в один из выбранных репутационных списков.
-
TCP SYN;
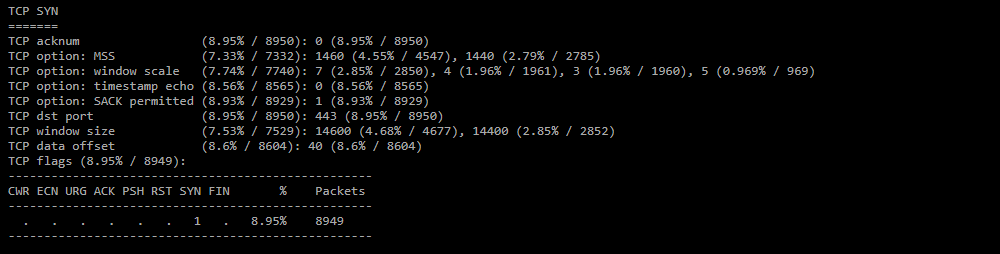
Статистика по TCP заголовкам для SYN пакетов. -
TCP SYN+ACK;
Статистика по TCP заголовкам для SYN+ACK пакетов аналогична статистике для SYN пакетов. -
Patterns per payload lengths;

Часто наблюдаемые шаблоны для пакетов с наиболее часто встречающейся длиной. -
Variable-Offset Patterns;

Часто наблюдаемые шаблоны в payload с переменным смещением. -
Fixed Byte Mask;

Смещения, по которым значение байта фиксировано, набор таких смещений и значений по ним образуем маску. -
Common Submask;
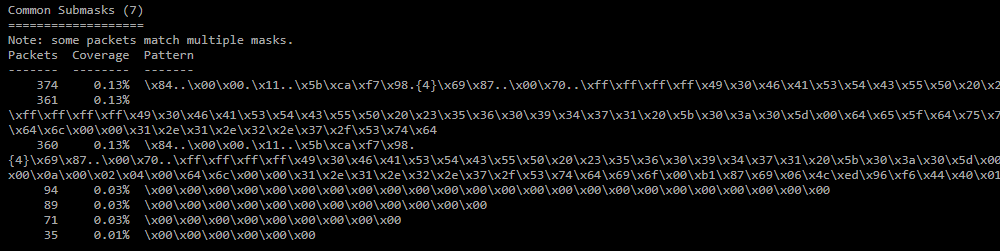
Среди масок ищутся похожие (50% совпадения регулярных выражений), и из них выделяется общая часть. -
Merged Submask;

Merged Submask образуются путем удаления избыточности из common submasks, например, aabb покрывается aab и остается только aab. -
Bloom filter signatures;
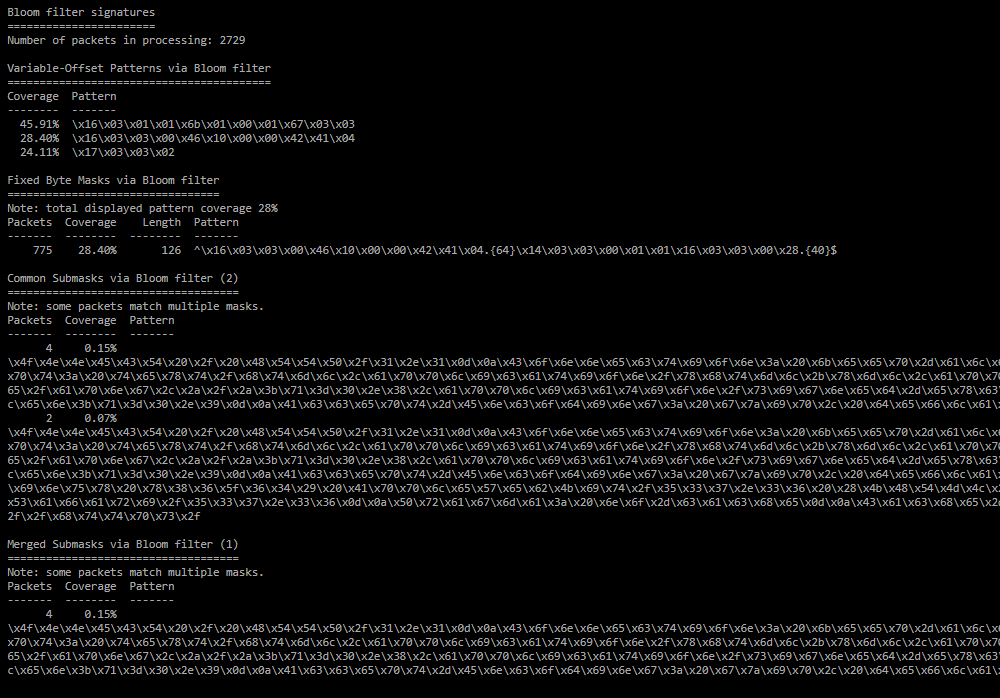
Список сигнатур для похожих пакетов, которые обнаружены при помощи фильтров Блума.- Number of packets in processing — количество пакетов, среди которых выбирались похожие;
- Variable-Offset Patterns via Bloom filter — Variable-Offset Patterns для похожих пакетов;

- Fixed Byte Masks via Bloom filter — Fixed Byte Mask для похожих пакетов;

- Common Submasks via Bloom filter — Common Submask для похожих пакетов;

- Merged Submasks via Bloom filter — Merged Submask для похожих пакетов.
